| Whether or not you can use SSI on your site depends on your provider. Ask your favourite support person if you can use SSI, what server software is used and if there are any special techniques, conditions or rules. For example, on my site I can only use SSI in files that have an .shtml extension instead of the normal .html one. You also have to ask what path to files to use.
Unfortunately, not all includes explained here work for all servers. For example, the #hide and #show includes are specific to WebStar. With Apache server software, you can achieve the same things by using #if and #endif.
更改时间格式
Before starting to use server side includes, you need to configure a number of things. For starters, choose a format for date and time you like (the #echo command is explained later in this chapter).
<!–#config timefmt=”%A, %d %B %Y at %H:%M:%S”–>
<!–#echo var=”date_gmt”–>
Below is a table of many of the options you can use. You can also include things like colons, commas and slashes as well as bits of text and HTML. You can mix the elements below at will.
| Element |
Value |
Example |
| %a |
Abbreviated day of the week |
Sun |
| %A |
Day of the week |
Sunday |
| %b |
Abbreviated month name |
Jan |
| %B |
Month in full |
January |
| %d |
Date |
1 (and not 01) |
| %H |
24-hour clock hour |
13 |
| %I |
12-hour clock hour |
1 |
| %j |
Decimal day of the year |
360 |
| %m |
Month number |
11 |
| %M |
Minutes |
08 |
| %p |
AM or PM |
AM |
| %S |
Seconds |
09 |
| %U |
Week of the year (also %W) |
49 |
| %w |
Day of the week number |
05 |
| %y |
Year of the century |
95 |
| %Y |
Year |
1995 |
| %Z |
Time zone |
EST |
Here are some more examples of different formats:
<!–#config timefmt=”Week %U of %y”–>
<!–#echo var=”date_gmt”–>
<!–#config timefmt=”%d/%m/%y, day %j of the year”–>
<!–#echo var=”date_gmt”–>
<!–#config timefmt=”%I:%S %p”–>
<!–#echo var=”date_gmt”–>
The last format you have set will remain valid throughout the rest of the page. However, unless you want to use the default format (which usually is something like 98/07/12:16:45:34) you will have to set your favourite time format in every page that uses server side includes that have to do with time.
更改大小格式
You can also specify the way file sizes are displayed.
<!–#config sizefmt=”bytes”–>
<!–#fsize file=”top.gif”–>
<!–#config sizefmt=”abbrev”–>
<!–#fsize file=”top.gif”–>
The #fsize include is explained later in this chapter. You can see that the “bytes” option gives the size in full in bytes, the “abbrev” option gives the size in kilobytes.
自定义错误消息
You can change the default error message to anything you want. Here is an example of changing the error message and then trying to include the non-existent file “nosuchfile.html”:
<!–#config errmsg=”Sorry, an error occurred. Please mail your complaints to webmaster@somewhere.net”–>
<!–#include file=”nosuchfile.html”–>
There is only one error message available. However, you can change the error message more than once in a single html file:
<!–#config errmsg=”Sorry, an error occurred including nosuchfile.html. Please mail your complaints to webmaster@somewhere.net”–>
<!–#include file=”nosuchfile.html”–>
<!–#config errmsg=”Sorry, an error occurred including nosuchfileagain.html. Please mail your complaints to webmaster@somewhere.net”–>
<!–#include file=”nosuchfileagain.html”–>
Specifying your own error messages will make it easier for you to spot and solve problems. If you want to use more than one error message, you have to make sure that you change the error message before the command it refers to.
包括文件
The include command allows you to dynamically insert other HTML files into the current HTML file. Use it like this:
<!–#include file=”file.shtml”–>
What path to use, again, depends on your provider. Normally it will be a path that is local to the server, so it will not include http://etc. The most sensible use of this command is to take standard bits of your pages such as headers and footer and put them in a separate file. On all of your pages you use the include command to include that file. That way, in order to change the footer on all pages, you only need to change one file. For example, you could make a simple text file that contains:
<P ALIGN=”center”>Copyright 1998 Tom, Dick and Harry<BR>
Please mail us at tom.dick@harry.com</P
You save this file as ssifooter.html and include it in your other files by using:
<!–#include file=”ssifooter.html”–>
The files you include can be plain text files or can include HTML. You don’t need to give them <HEAD> and <BODY> tags, just put in whatever you want to insert. In these files you can use whatever HTML you want and you can make links, etc.
隐藏 / 显示
With the Hide and Show commands you can avoid that your reader sees certain parts of the document:
<P>Now you see me, <!–#hide–> This text is not shown. <!–#show–> now you don’t.</P
Show and Hide can be used to temporary exclude parts of your document. Hide and Show only work under WebStar, so I cannot show you an example here.
根据时间隐藏和显示
The next example shows how to display bits of HTML only after certain days. Comparisons like this always use the default time format of 1998/07/24:17:34:45 no matter what you have done with the timefmt option.
<!–#hide–>
<!–#show after=”1998/06/30″–>
This text is shown after 30 June 1998.
<!–#show–>
<!–#hide–>
<!–#show after=”1999/06/30″–>
This text is shown after 30 June 1999.
<!–#show–>
Or you can show and hide things on specific days using a combination of ‘hide after’ and ‘show after’:
<!–#hide–>
<!–#show during=”1998/07/12″–>
This text is shown on 12 July 1998.
<!–#show–>
<!–#hide–>
<!–#show during=”1998/07/13″–>
This text is shown on 13 July 1998.
<!–#show–>
<!–#hide–>
<!–#show during=”1998/07/14″–>
This text is shown on 14 July 1998.
<!–#show–>
As you can see, you do not have to specify a full date and time but only what is relevant for you. If you would want to show something during 1998 you could use: during=”1998″.
依据时间隐藏和显示
Here is an example of how to show a bit of text only to a user of Netscape’s Navigator:
<!–#hide–>
<!–#show var=”http_user_agent” operator=”contains”
value=”nav”–>
Welcome Netscape Navigator user!
<!–#show–>
<!–#hide–>
<!–#show var=”http_user_agent” operator=”contains”
value=”MSIE”–>
Welcome Internet Explorer user!
<!–#show–>
As you can see in this example, the output of Webstar is by default on. That’s why you start any of these examples by switching the output of (#hide) and then switching it on again if the appropriate condition is fulfilled. At the end of the example you switch the output on again with a #show include. Again, show and hide do not work under Apache so I cannot show you the result here.
随机隐藏和显示
Show and Hide can also be used at random:
<!–#hide–>
<!–#show var=”random” op=”<” value=”50″ –>
Heads
<!–#hide–>
<!–#show var=”random” op=”=>” value=”50″ –>
Tails
<!–#show–>
If you do a couple of reloads, you should see the text change. Of course you can use the same thing to show and hide images or any other HTML. The number that is used by Webstar is a random number ranging from 1 to 99 inclusive. Here is an example for three random texts:
<!–#hide–>
<!–#show var=”random” op=”<” value=”33″ –>
To be or not to be,
<!–#hide–>
<!–#show var=”random” op=”=>” value=”34″ –>
<!–#hide var=”random” op=”>” value=”66″ –>
that’s the question,
<!–#hide–>
<!–#show var=”random” op=”>” value=”66″ –>
my dear Watson.
<!–#show–>
更多的隐藏和显示
In fact you can show and hide text at will using any of the environment variables (see the section on Echo below). This example shows a bit of text to a user with IP address 195.99.40.125:
<!–#hide–>
<!–#show var=”remote_addr” operator=”=” value=”195.99.40.125″–>
Welcome BTinternet user!
<!–#show–>
If you have friends with fixed IP addresses you can leave messages especially for them in the same manner. Finally, you should know which operators are available:
| Operator |
Meaning |
| “contains” or “con” |
variable contains the value string |
| “starts with” or “start” |
variable starts with the value string |
| “ends with” or “end” |
variable ends with the value string |
| “=” or “==” |
variable equals the value string |
| “!=” or “<>” |
variable does not equal the value string |
| “<“ |
variable is less than the value string |
| “<=” or “=<“ |
variable is less than or equal to the value string |
| “>” |
variable is greater than the value string |
| “>=” or “=>” |
variable is greater than or equal to the value string |
If 和 Endif
Because this server runs Apache I could not show the examples of #hide and #show. I can, however, demonstrate the #if and #endif includes (if and endif, in turn, do not work under Webstar):
<!–#config timefmt=”%A”–>
<!–#if expr=”$date_gmt = Friday” –>
Hang in there, it’s almost weekend
<!–#elif expr=”($date_gmt = Saturday) || ($date_gmt = Sunday)” –>
Have a nice weekend
<!–#else –>
Have a good day
<!–#endif –>
Hang in there, it’s almost weekend Have a nice weekend Have a good day
The first thing you will notice is that the #if include, opposite to the #hide and #show, does use the date as formatted with timefmt. This has some clear advantages. You can also see that this example is a bit easier to understand the #show and #hide spaghetti that WebStar seems to need. Note that the #if and #endif are obligatory, the #elif and #else are optional. This example uses date_gmt which is London time -ignoring summertime- rather than date_local which depends on where the server is.
The following operators are available:
| Operator |
Meaning |
| string1 = string2 |
string1 equals string2 |
| string1 != string2 |
string1 does not equal string2 |
| string1 < string2 |
string1 is less than string2 |
| string1 <= string2 |
string1 is less than or equal to string2 |
| string1 > string2 |
string1 is greater than string2 |
| string1 >= string2 |
string1 is greater than or equal to string2 |
If, Endif 和环境变量
you can use the #if include to show different information to different browsers. Each browser sets the environment variable http_user_agent differently. This is how Netscape Navigator 4.04, Microsoft Internet Exploder and Apple’s Cyberdog respectively do it:
Mozilla/4.04 (Macintosh; I; PPC, Nav)
Mozilla/4.0 (compatible; MSIE 4.0; Mac_PowerPC)
Cyberdog/2.0 (Macintosh; PPC)
As you can see these are all the Macintosh versions. By the way, this is what your own browser makes of http_user_agent: . So this is how to show different information to different browsers:
<!–#if expr=”$HTTP_USER_AGENT=/MSIE/ ” –>
Fight the Microsoft Monopoly. Get Netscape!
<!–#elif expr=”$HTTP_USER_AGENT=/Nav/ ” –>
Welcome Netscape Navigator user!
<!–#elif expr=”$HTTP_USER_AGENT=/Cyberdog/ ” –>
Welcome Apple Cyberdog user!
<!–#else –>
Welcome! So what browser are you using?
<!–#endif –>
Fight the Microsoft Monopoly. Get Netscape! Welcome Netscape Navigator user! Welcome Apple Cyberdog user! Welcome! So what browser are you using?
Note that the /Nav/ I am looking for here is produced by Netscape Navigator, which is Communicator without the news, mail and webeditor modules. The above is obviously not an exhaustive list of browsers, which is why there is also an #else include for all the browsers that are not covered.
The two slashes around MSIE, Nav and Cyberdog in the example above means that the second string is interpreted as a regular expression, commonly used under Unix. In this case it checks if http_user_agent contains that string.
Set
The #set include can be used to create your own variables and assign them a value. Variables can be printed or can be used in #if statements:
<!–#set var=”carmodel” value=”Mercedes” –>
<!–#echo var=”carmodel” –><BR>
<!–#if expr=”$carmodel = Mercedes” –>
That’s a jolly nice car
<!–#endif –>
That’s a jolly nice car
The $ sign in the #if include is needed to ensure that “carmodel” is interpreted as a variable, not as a string.
Echo
ECHO can be used to insert information from the browser and the server into your document, the so-called environment variables. The following possibilities are available:
Document Name: <!–#echo var=”document_name”–>
Document URI: <!–#echo var=”document_uri”–>
Local Date: <!–#echo var=”date_local”–>
GMT Date: <!–#echo var=”date_gmt”–>
Last Modified: <!–#echo var=”last_modified”–>
Server Software: <!–#echo var=”server_software”–>
Server Name: <!–#echo var=”server_name”–>
Server Protocol: <!–#echo var=”server_protocol”–>
Server Port: <!–#echo var=”server_port”–>
Gateway Interface: <!–#echo var=”gateway_interface”–>
Request Method: <!–#echo var=”request_method”–>
Script Name: <!–#echo var=”script_name”–>
Remote Host: <!–#echo var=”remote_host”–>
Remote Address: <!–#echo var=”remote_addr”–>
Remote User: <!–#echo var=”remote_user”–>
Content Type: <!–#echo var=”content_type”–>
Content Length: <!–#echo var=”content_length”–>
HTTP Accept: <!–#echo var=”http_accept”–>
HTTP User Agent (Browser): <!–#echo var=”http_user_agent”–>
HTTP Cookie: <!–#echo var=”http_cookie”–>
Unescaped query string: <!–#echo var=”query_string_unescaped”–>
Query String: <!–#echo var=”query_string”–>
Path Info: <!–#echo var=”path_info”–>
Path Translated: <!–#echo var=”path_translated”–>
Referer: <!–#echo var=”referer”–>
Forwarded: <!–#echo var=”forwarded”–>
Document Name:
Document URI:
Local Date:
GMT Date:
Last Modified:
Server Software:
Server Name:
Server Protocol:
Server Port:
Gateway Interface:
Request Method:
Script Name:
Remote Host:
Remote Address:
Remote User:
Content Type:
Content Length:
HTTP Accept:
HTTP User Agent (Browser):
HTTP Cookie:
Unescaped query string:
Query String:
Path Info:
Path Translated:
Referer:
Forwarded:
Not all ECHO commands always result in information being printed. This can depend on the server, on your browser and on the way you reached this page. The #echo include works both under WebStar and Apache.
Print Environment
If you want to print the entire environment, you do not need to use a whole list of #echo includes. Instead you can use this shortcut.
<PRE> <!–#printenv –> </PRE>
Note that the environment includes the variable “carmodel” that was defined in an earlier example.
执行脚本
You can use a server side include to run a script. This is what I use on my homepage:
<!–#exec cgi=”ssi.demo.cgi”–>
The CGI script (which is in Perl 5) opens a file with a dozen quotes, selects one at random and prints it to the page. The script, by the way, is courtesy of Matt Wright who offers a brilliant collection of scripts.
文件大小
You can insert the size of a file in this way:
<!–#fsize file=”top.gif”–>
This inserts the size of the file top.gif (the logo at the top of this page). As explained earlier in this chapter, you can determine if the size is displayed in full bytes or abbreviated in kilobytes or megabytes.
文件日期
You can insert the date of a file in this way:
<!–#flastmod file=”top.gif”–>
This inserts the date and the time the file top.gif (the logo at the top of this page) was last modified. The format of the date and time can be customized by you as explained earlier in this chapter.
This page has been translated into Spanish language by Maria Ramos from Webhostinghub.com.
|
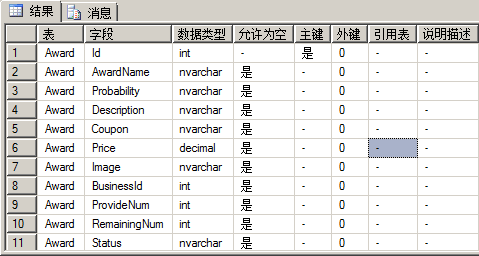


 因为系统架构的原因,OpenVZ的linux vps默认是不允许在客户在vps自行修改系统时间,当执行修改时间的操作时,会出错
因为系统架构的原因,OpenVZ的linux vps默认是不允许在客户在vps自行修改系统时间,当执行修改时间的操作时,会出错