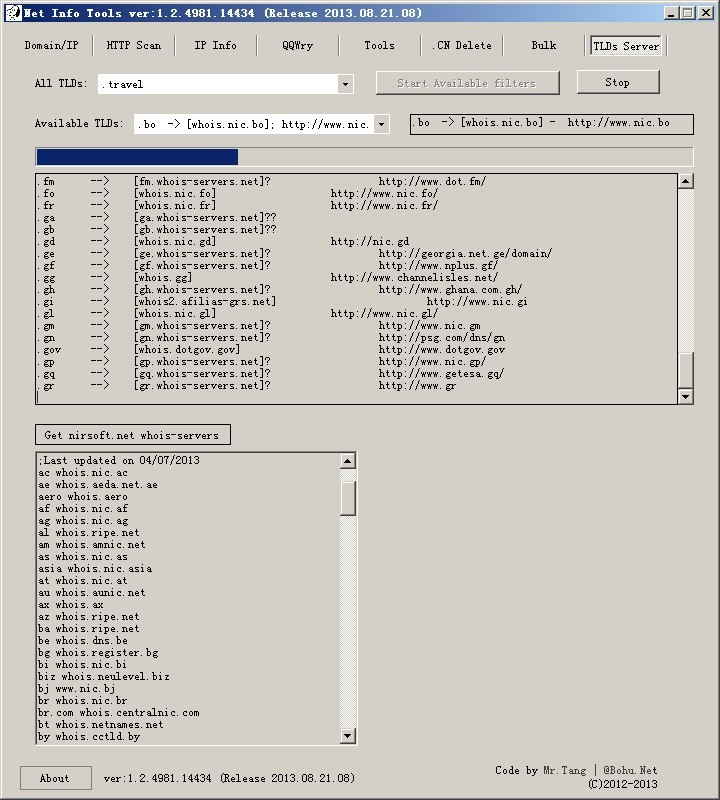
Windows Internet服务器安全配置
原理篇
我们将从入侵者入侵的各个环节来作出对应措施
一步步的加固windows系统.
加固windows系统.一共归于几个方面
1.端口限制
2.设置ACL权限
3.关闭服务或组件
4.包过滤
5.审计
我们现在开始从入侵者的第一步开始.对应的开始加固已有的windows系统.
1.扫描
这是入侵者在刚开始要做的第一步.比如搜索有漏洞的服务.
对应措施:端口限制
以下所有规则.都需要选择镜像,否则会导致无法连接
我们需要作的就是打开服务所需要的端口.而将其他的端口一律屏蔽
2.下载信息
这里主要是通过URL SCAN.来过滤一些非法请求
对应措施:过滤相应包
我们通过安全URL SCAN并且设置urlscan.ini中的DenyExtensions字段
来阻止特定结尾的文件的执行
3.上传文件
入侵者通过这步上传WEBSHELL,提权软件,运行cmd指令等等.
对应措施:取消相应服务和功能,设置ACL权限
如果有条件可以不使用FSO的.
通过 regsvr32 /u c:\windows\system32\scrrun.dll来注销掉相关的DLL.
如果需要使用.
那就为每个站点建立一个user用户
对每个站点相应的目录.只给这个用户读,写,执行权限,给administrators全部权限
安装杀毒软件.实时杀除上传上来的恶意代码.
个人推荐MCAFEE或者卡巴斯基
如果使用MCAFEE.对WINDOWS目录所有添加与修改文件的行为进行阻止.
4.WebShell
入侵者上传文件后.需要利用WebShell来执行可执行程序.或者利用WebShell进行更加方便的文件操作.
对应措施:取消相应服务和功能
一般WebShell用到以下组件
WScript.Network
WScript.Network.1
WScript.Shell
WScript.Shell.1
Shell.Application
Shell.Application.1
我们在注册表中将以上键值改名或删除
同时需要注意按照这些键值下的CLSID键的内容
从/HKEY_CLASSES_ROOT/CLSID下面对应的键值删除
5.执行SHELL
入侵者获得shell来执行更多指令
对应措施:设置ACL权限
windows的命令行控制台位于\WINDOWS\SYSTEM32\CMD.EXE
我们将此文件的ACL修改为
某个特定管理员帐户(比如administrator)拥有全部权限.
其他用户.包括system用户,administrators组等等.一律无权限访问此文件.
6.利用已有用户或添加用户
入侵者通过利用修改已有用户或者添加windows正式用户.向获取管理员权限迈进
对应措施:设置ACL权限.修改用户
将除管理员外所有用户的终端访问权限去掉.
限制CMD.EXE的访问权限.
限制SQL SERVER内的XP_CMDSHELL
7.登陆图形终端
入侵者登陆TERMINAL SERVER或者RADMIN等等图形终端,
获取许多图形程序的运行权限.由于WINDOWS系统下绝大部分应用程序都是GUI的.
所以这步是每个入侵WINDOWS的入侵者都希望获得的
对应措施:端口限制
入侵者可能利用3389或者其他的木马之类的获取对于图形界面的访问.
我们在第一步的端口限制中.对所有从内到外的访问一律屏蔽也就是为了防止反弹木马.
所以在端口限制中.由本地访问外部网络的端口越少越好.
如果不是作为MAIL SERVER.可以不用加任何由内向外的端口.
阻断所有的反弹木马.
8.擦除脚印
入侵者在获得了一台机器的完全管理员权限后
就是擦除脚印来隐藏自身.
对应措施:审计
首先我们要确定在windows日志中打开足够的审计项目.
如果审计项目不足.入侵者甚至都无需去删除windows事件.
其次我们可以用自己的cmd.exe以及net.exe来替换系统自带的.
将运行的指令保存下来.了解入侵者的行动.
对于windows日志
我们可以通过将日志发送到远程日志服务器的方式来保证记录的完整性.
evtsys工具(https://engineering.purdue.edu/ECN/Resources/Documents)
提供将windows日志转换成syslog格式并且发送到远程服务器上的功能.
使用此用具.并且在远程服务器上开放syslogd,如果远程服务器是windows系统.
推荐使用kiwi syslog deamon.
我们要达到的目的就是
不让入侵者扫描到主机弱点
即使扫描到了也不能上传文件
即使上传文件了不能操作其他目录的文件
即使操作了其他目录的文件也不能执行shell
即使执行了shell也不能添加用户
即使添加用户了也不能登陆图形终端
即使登陆了图形终端.拥有系统控制权.他的所作所为还是会被记录下来.
额外措施:
我们可以通过增加一些设备和措施来进一步加强系统安全性.
1.代理型防火墙.如ISA2004
代理型防火墙可以对进出的包进行内容过滤.
设置对HTTP REQUEST内的request string或者form内容进行过滤
将SELECT.DROP.DELETE.INSERT等都过滤掉.
因为这些关键词在客户提交的表单或者内容中是不可能出现的.
过滤了以后可以说从根本杜绝了SQL 注入
2.用SNORT建立IDS
用另一台服务器建立个SNORT.
对于所有进出服务器的包都进行分析和记录
特别是FTP上传的指令以及HTTP对ASP文件的请求
可以特别关注一下.
本文提到的部分软件在提供下载的RAR中包含
包括COM命令行执行记录
URLSCAN 2.5以及配置好的配置文件
IPSEC导出的端口规则
evtsys
一些注册表加固的注册表项.
实践篇
下面我用的例子.将是一台标准的虚拟主机.
系统:windows2003
服务:[IIS] [SERV-U] [IMAIL] [SQL SERVER 2000] [PHP] [MYSQL]
描述:为了演示,绑定了最多的服务.大家可以根据实际情况做筛减
1.WINDOWS本地安全策略 端口限制
A.对于我们的例子来说.需要开通以下端口
外->本地 80
外->本地 20
外->本地 21
外->本地 PASV所用到的一些端口
外->本地 25
外->本地 110
外->本地 3389
然后按照具体情况.打开SQL SERVER和MYSQL的端口
外->本地 1433
外->本地 3306
B.接着是开放从内部往外需要开放的端口
按照实际情况,如果无需邮件服务,则不要打开以下两条规则
本地->外 53 TCP,UDP
本地->外 25
按照具体情况.如果无需在服务器上访问网页.尽量不要开以下端口
本地->外 80
C.除了明确允许的一律阻止.这个是安全规则的关键.
外->本地 所有协议 阻止
2.用户帐号
a.将administrator改名,例子中改为root
b.取消所有除管理员root外所有用户属性中的
远程控制->启用远程控制 以及
终端服务配置文件->允许登陆到终端服务器
c.将guest改名为administrator并且修改密码
d.除了管理员root,IUSER以及IWAM以及ASPNET用户外.禁用其他一切用户.包括SQL DEBUG以及TERMINAL USER等等
3.目录权限
将所有盘符的权限,全部改为只有
administrators组 全部权限
system 全部权限
将C盘的所有子目录和子文件继承C盘的administrator(组或用户)和SYSTEM所有权限的两个权限
然后做如下修改
C:\Program Files\Common Files 开放Everyone 默认的读取及运行 列出文件目录 读取三个权限
C:\WINDOWS\ …